Introduction
For every master student, there is one thing standing in between them and the end of their student life: “the thesis”. For months, or even years, a student tries to analyse a certain topic in the best way possible. And after this long and difficult journey, the student receives his reward at his graduation: “the diploma”. For this graduation, the student dresses up nicely, invites his parents, and simply wants to sit through the ceremony and receive the diploma and go home.
However, Inger Leemans , one of the speakers at the event, realized that all the theses together are a very interesting data set to analyse. She contacted us to help analyse the theses. In this blog, I would like to present the most interesting results from the analysis.
Description of the data set
Theses were analysed from the following departments: Classics and Ancient Civilizations, History, Arts & Culture, Literary studies, Language and Communications. In total, around 100 theses were analyzed.
Thesis length

When analyzing the thesis length, defined as the number of words in a thesis, one prejudice about theses was found to be true: theses are long.
On average, theses were 36.000 words long, with the departements of History and Communication being the most wordiest.
Average sentence length

On average, sentences contained 14 words, which is relatively long. Of course, some were longer, please do try to read the long sentence in the slide above this sentence.
Positive and negative words
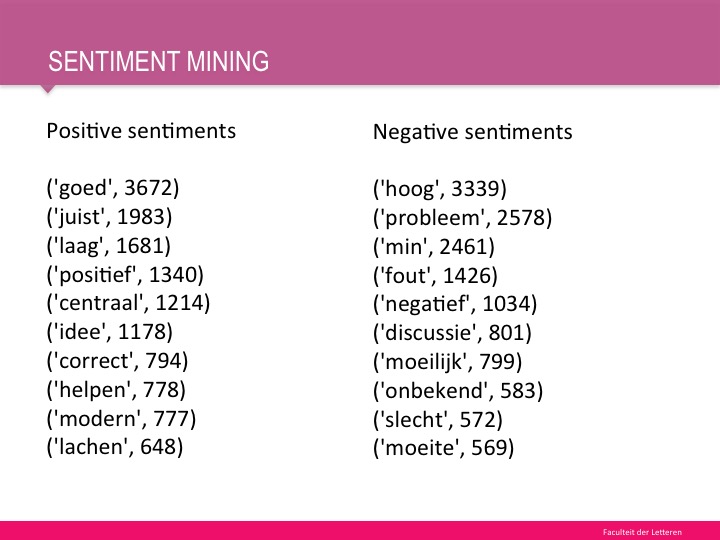
We also simply counted the positive and negative words from all the theses.
Most positive and most negative thesis

By using the positive and negative words from the previous section, we can determine the most positive and negative thesis. We simply calculated the ratio of positive and negative words in each thesis. For example, if a thesis had 57 positive words, and 43 negative words, the positive word ratio would be 57%. It’s actually quite surprising that we were able to find a positive and negative thesis using such a simple heuristic.
Mapping named entities to google maps
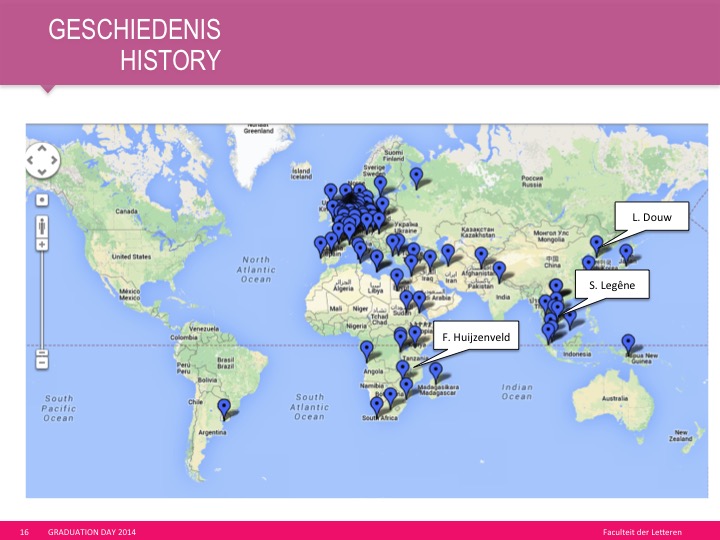
A completely different element in theses are the named entities. The most common named entities are persons and countries. We extracted all the named entities from each thesis, looked for their coordinates, and plotted them on a map. the results were very informative. For example, Inger Leemans could indicate which colleague was working on which area.
Mistakes happen
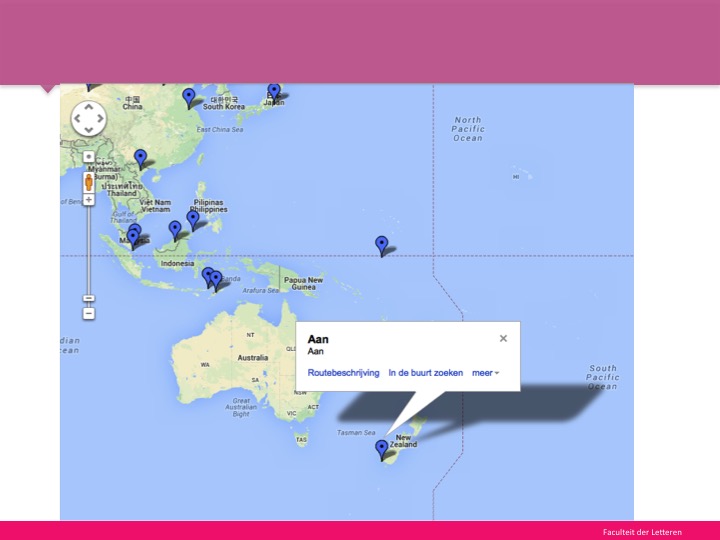
Finally, please be aware that algorithms make mistakes. In the slide above, we see that the Dutch preposition ‘aan’ has been tagged as a named entity, because there is apparently also a place called ‘Aan’ in New Zealand.
Acknowledgements
Many thanks go to
Piek Vossen
Ruben Izquierdo
Paul Huygen
The pictures were taken from the presentation used at the graduation ceremony. Many thanks go to Inger Leemans for making the slides public.