Last week Motherboard published an article featuring a paper by PhD student Emiel van Miltenburg. (Later also published by the Dutch Motherboard.) Van Miltenburg found that the data that is commonly used to train automatic image description systems contain stereotypes and biases, leading to the question whether computers will be biased, too.
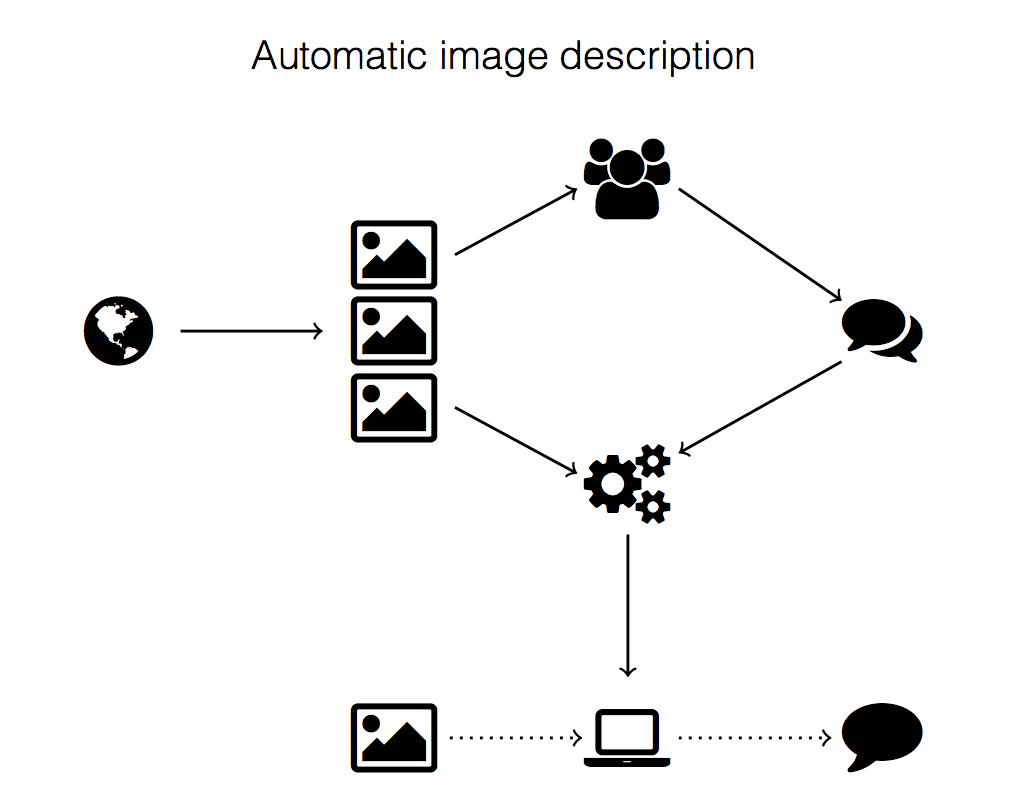 Illustration from Stereotyping and Bias in the Flickr30k Dataset, presentation by: Emiel van Miltenburg at MMC 2016 @ LREC 2016
Illustration from Stereotyping and Bias in the Flickr30k Dataset, presentation by: Emiel van Miltenburg at MMC 2016 @ LREC 2016
It is not clear whether machines are already able to learn those stereotypes, but it is important to be aware of this possibility in the future. We will continue studying stereotypes and perspectives in language, so that we can keep machines from becoming biased. Van Miltenburg wrote a longer response to the Motherboard article in Dutch here and in English here.