The workshop “SLT-1: Semantics of the Long Tail”, initiated by Piek Vossen, Filip Ilievski, and Marten Postma from VU Amsterdam, has been accepted at the next edition of the IJCNLP conference, to be held in Taipei, Taiwan on November 27 – December 1, 2017. The SLT-1 workshop is co-organized by eight external internationally recognized researchers: Eduard Hovy, Chris Welty, Martha Palmer, Ivan Titov, Philipp Cimiano, Eneko Agirre, Frank van Harmelen and Key-Sun Choi. This workshop aims at a critical discussion on the relevance and complexity of various long tail phenomena in text, i.e. hard, though non-frequent cases that need to be resolved for correct language interpretation, but are neglected by current systems. More information about the SLT-1 workshop can be found at: http://www.understandinglanguagebymachines.org/semantics-of-the-long-tail/
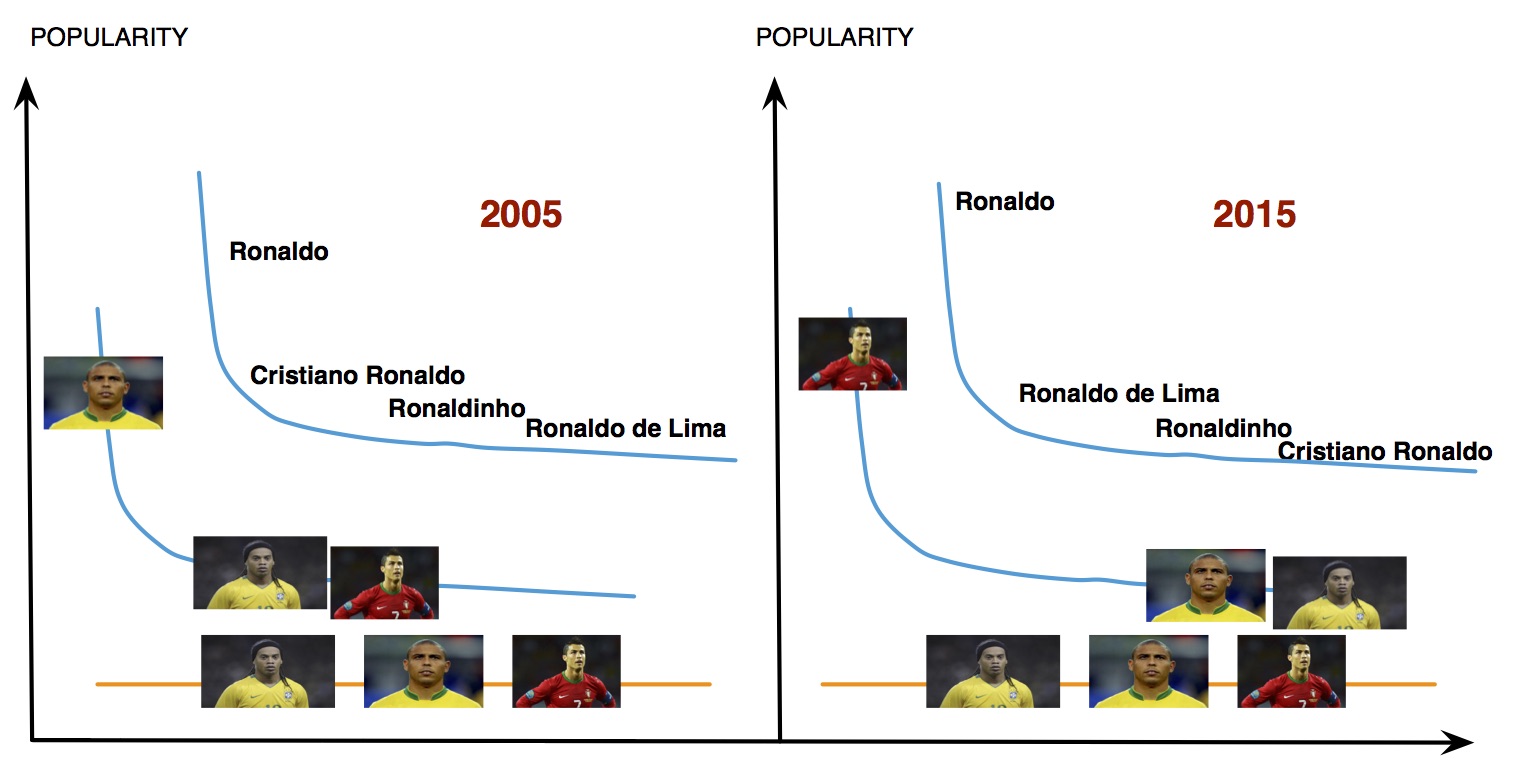
We often use the same expression (e.g. “Ronaldo”) to refer to multiple different concepts or instances. In our communication, several of these concepts and instances are very frequent (we refer to these as “head”), while many others appear only seldomly and within a very specific context (we refer to these as “tail”). The head and the tail are distributional and change over time. In this example, the Brazilian soccer player was by far the most popular Ronaldo in 2005, while it is the Portuguese in 2015. In those corresponding years, using the form “Ronaldo” without any context would clearly refer to those head interpretations. But how to interpret text about a local carpenter in a small village in Colombia that also shares this name? How can we teach machines to grasp the context and decide for a tail interpretation? This is an extremely complex challenge of NLP today.
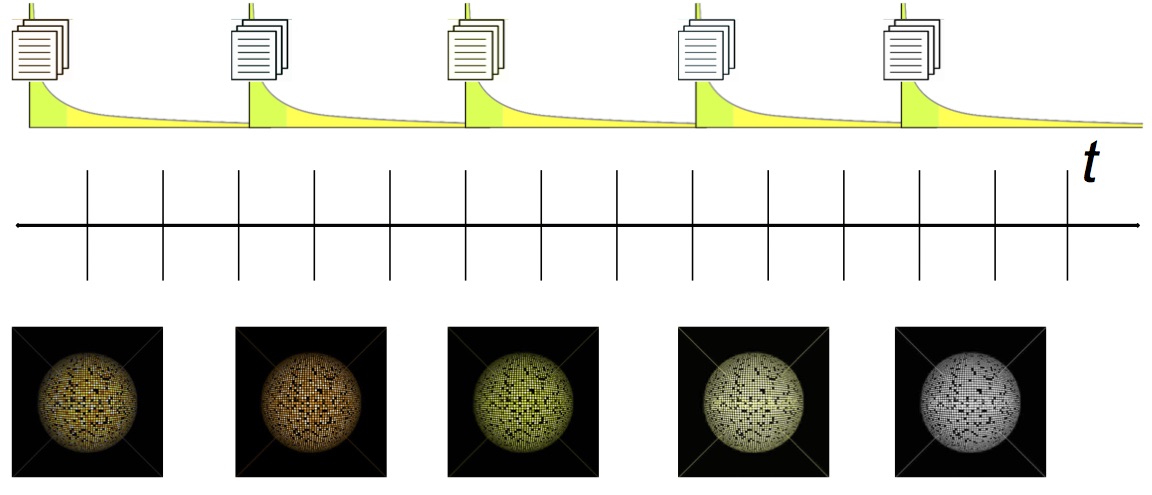
At each point in time, there is a distributional long tail of our language use. We communicate about a few popular things much more than about the majority of the rest. NLP datasets that are used for training and testing systems mirror this imbalance of frequency, and mainly represent the popular world at the time. In turn, this causes NLP systems to unfortunately also inherit that bias, thus performing very well on the “head” interpretations, and much worse on the “tail.
Aside from the relevance and urgency for the semantic NLP community to improve our understanding and the performance on the wide range of long tail phenomena in language, we also value shared tasks in which systems are challenged to perform well on long tail phenomena. We are hence hosting SemEval-2018 task 5 “Counting Events and Participants within Highly Ambiguous Data covering a very long tail”, which is a “referential quantification” task that requires systems to establish the meaning, reference and identity of events and participants in news articles. Based on a set of questions and corresponding documents, the participant systems need to provide a numeric answer together with the supporting mentions of the answer events in the documents.
If you share the opinion that this topic is crucial for the future of semantic NLP, please consider joining us, by participating in this SemEval task, and/or submitting to the “Semantics of the Long Tail” workshop.