As a joint initiative with the Digital Humanites Group at Fondazione Bruno Kessler (FBK, Trento), we set up a collaboration with the Italian Ministry of Education, Universities and Research (MIUR) on the automatic analysis of linguistic data contained in the answers given by the participants of the public consultation “La Buona Scuola” (#labuonascuola).
#labuonascuola has been the biggest on-line public consultation ever realized in Europe for the development of policies for public school in Italy. 207.000 people took part to the on-line questionnaire which included also a set of open question to which people coud answer freely using natural language. Overall, more than 5 million words (775.000 texts) were provided by the users. Such an amount of data cannot be analysed by hand, not event in “reasonable time”. Manual analysis is prone to errors and wrong analysis of the data can impact the final recommendations to policy makers. So which alternatives? PIERINO (Platform for the Extraction and Retrieval of Online Information), it’s the answer!
All linguistic data from the open field questions were analysed by means of a pipeline of Natural Language Processing tools such as a lemmatizer, a part-of-speech tagger, a key-concept extractor, and a topic modeller. Part of these tools have been implemented in FBK (i.e. TextPro) while for topic modelling we adopted Mallet. The outcome is PIERINO a graphical interface which has been used by the people of MIUR to retrive and collect all important information. PIERINO provides a set of intuitive visualisations to browse and search the data in an online environment. Furthermore, the information thus collected will be used to assist policy makers in the development of new bills concerning the school in Italy.
End of the story? Not at all. The amount of data collected can be further and better analyzed. One intriguing research question is: what is the story 207.000 citizens have told to the MIUR towards which directions policies for schools should go in Italy? An important aspect to start answering this question concerns the analysis of the content of these proposals. Topic modeling and keyword extraction are the first steps, we need to move forward. We need to start aggregating similar proposals per content, compare them (supporting and contrasting ideas), identify the sources of the proposals (are teachers having different proposals than students?), we need to focus on modality (how is the message conveyed?), negation scope and sentiment analysis as well. Some of the pending issues are common and strictly connected to the SPINOZA Storyline project. It is still a long journey and a long story to be told.
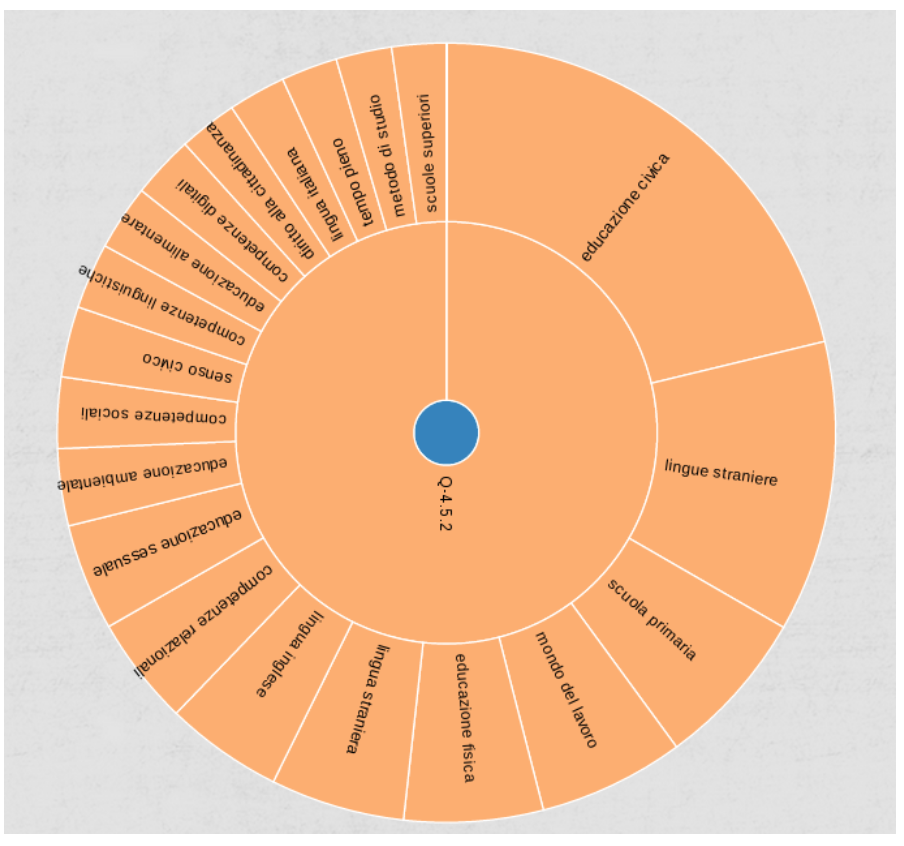
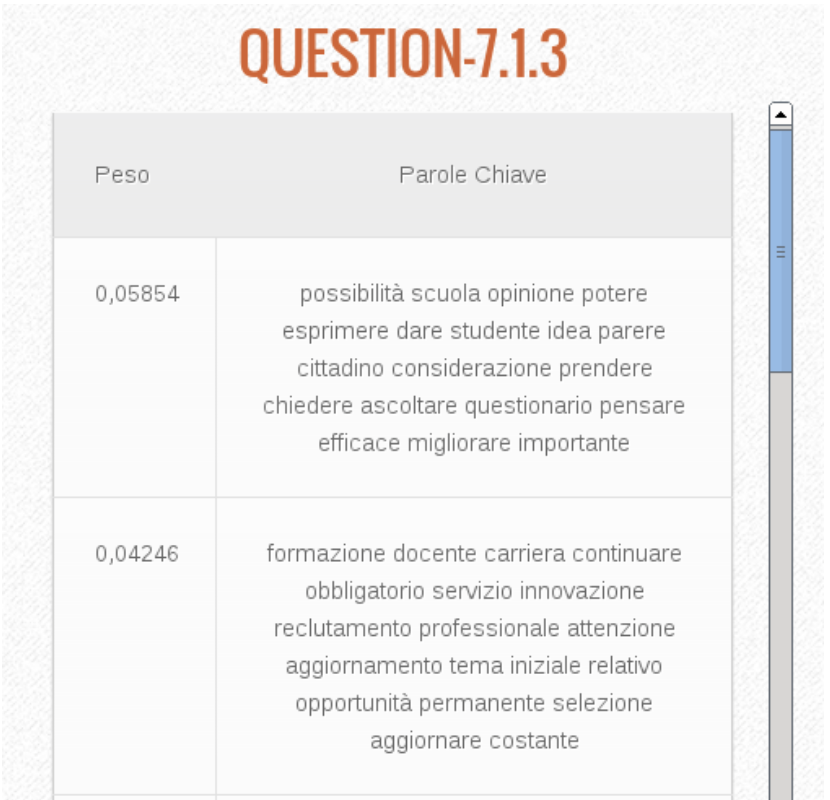
What follows are some screenshots of from PIERINO (in order: keyword association with a predefined set of concepts provided by the MIUR, keyword extraction for the question “What is learned at school. What is missing?” and, finally, extracted topics for the question “What is missing in the public consultation “La Buona Scuola”?”). 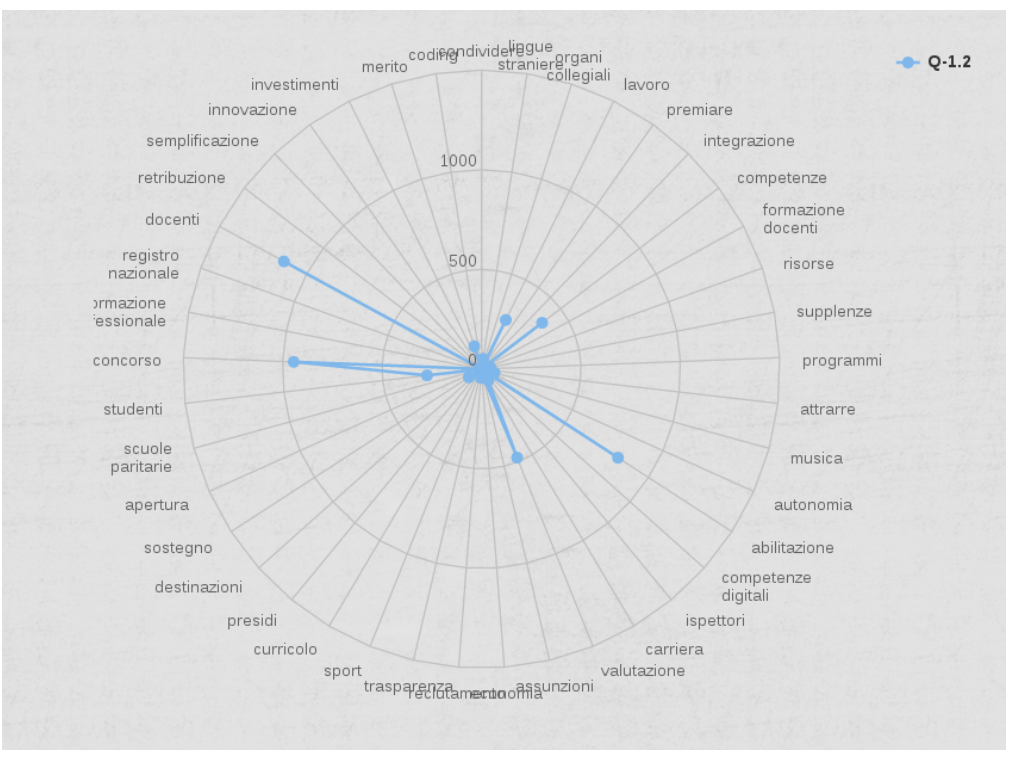
Contact: Tommaso Caselli [t DOT caselli AT vu DOT nl]
Comments